Deprecating line coverage
Line coverage is typically the first structured metric looked at, and it provides a rough and imprecise measure of how thoroughly the test harness exercises the code. Briefly, line coverage is the answer to the question was code at this line ever run? The most important insight is finding the code that is not at all exercised in testing, but it can also be used as a coarse profiling tool by highlighting what lines are run more often and could warrants more optimization or other improvements. However, the unit of line is flawed in a couple of aspects, and it is time we stop using it and instead favour better metrics.
The line is too coarse
The first problem is the line itself. What does it mean exactly that a line is executed? Consider this C snippet:
double safediv(double a, double b) {
if (b == 0) return 0.0;
return a / b;
}Clearly line 2 is executed regardless of the value of b, but it is
not until b both zero and non-zero all of line 2 is executed.
This issue would not be if the return 0.0 was on a separate line,
but the function as it is written is perfectly fine. Most languages
don’t really consider lines a construct of the language anyway, and
even fewer as syntactically or semantically significant. For example,
you can remove most newlines (and whitespaces) from C programs and it
would not change anything for the compiler, which is used to great
effect in the The International Obfuscated C Code
Contest. The newline problem goes both ways,
as seen in the GCC bug report
117415. This
minimal example reproduces the problem on GCC 12.2:
int arr[10];
int *foo() {
return arr;
}
int main(void) {
int *a = arr;
*foo()=
*a;
&a;
}$ gcc ex.c --coverage -o ex && ./ex && gcov -t ex
1: 5:int main(void) {
1: 6: int *a = arr;
2: 7: *foo()=
1: 8: *a;
-: 9: &a;
-: 10:}The first column is the execution count, and the *foo() = line
apparently gets executed twice. This is obviously not the case, which
can be demonstrated by sprinkling newlines everywhere:
$ gcc ex2.c --coverage -o ex2 && ./ex2 && gcov -t ex2
1: 5:int main(void) {
1: 6: int *a = arr;
-: 7: *
1: 8: foo()
1: 9: =
1: 10: *a;
-: 11: &a;
-: 12:}A clear improvement over line coverage would be statement coverage: was this statement ever run? I choose to include expressions in this definition as it does not make too much sense to keep them apart. This would, along with decision coverage (has every if/boolean taken both then and else?), fix the attribution and counting problem, but it brings a few new problems: how to report coverage, the cost of coverage, and signal-to-noise.
The statement is too noisy
Let’s start with the easy one, the cost of coverage. Explicitly measuring every statement (and expression!) would mean that the instrumentation must interleave every operation, possibly with atomics, which would balloon binary size and make programs significantly slower. Some overhead is certainly to be expected, but nobody will turn on coverage if it means tests become too slow to practically run. Note that GCC today does not instrument lines either (which is why it gets the attribution wrong in the example), which will be discussed later.
Presenting the report is another problem. Line coverage is simple because it is sufficient to simply add a count column (or red/green for coverage) when annotating the source file, which is all the structure we need. Since statements may span multiple lines, and a line may have multiple statements, reports must now know how to break up or overlay parts of a line, which breaks the relationship with the original source.
Finally, there’s signal-to-noise. The ratio of covered/uncovered is a useful data point when deciding what module, file, or function to investigate. Measuring statements does not interfere with this, but not all statements are created equal. Some statements carry much more weight in the program, especially those in precondition checks and error handling paths. Measuring statements skews ratios towards long series of straight line code, happy paths, and underemphasise short branches. Consider this program with roughly 20 statements and expressions:
int main() {
int a = foo1();
int b = foo2();
int c = foo3();
int d = foo4() + foo5();
int e = a + b*c - d;
int f = e > b ? foo6() : foo7();
if (err(f)) exit(EXIT_FAILURE);
}I would say coverage-wise this has three main points of interest:
foo6(), foo7(), and the exit() (which, granted, correspond to
decision coverage). Missing either of those would still give 19/20
statements which looks like a fairly well covered function and
underemphasises an important part of it. Worse yet, statement coverage
can cover all statements and never exercise the case where err(f)
is false and the normal end-of-main is reached. Oops.
Blocks all along
Enter the basic block. The research in this area does not really consider line or even statement coverage very much. Rather, the fundamental piece is the basic block. A basic block is defined as an uninterruptible stream of instructions such that when you enter a basic block, you will execute every instruction in order until the end of the basic block. This is how the compiler analyses the program, and how coverage is measured by GCC. Instead of recording every statement, GCC injects code on the entry- and exit of basic blocks. The basic blocks are then mapped back to source lines, which sometimes get wrong like in the example in this post.
I think the basic block is the obvious unit for coverage, and that node coverage (or block coverage) should take over as the most basic metric. Node coverage is the answer to the question has every node been visited? This answers all the problems brought on by statement coverage. By achieving block coverage you also achieve line coverage - every line must be a part of a block, and by visiting all block all lines must have been visited, too.
Per-node instrumentation is already how GCC measures coverage, and the overhead is acceptable. Instructions are only inserted at the beginning or end of a block, and there are far fewer blocks per function than statements. Small functions tend to have less than 10 blocks, and complicated functions may have a few hundred. There is no limit on the number of blocks, but for most practical purposes the number of blocks can be considered small, and by extension, cheap.
Signal-to-noise is also good as the contribution of a block is not dependent on the number of instructions in a block. A long sequence of non-branching code will usually be represented as a single block, where an 4-term conditional usually ends up as 4 blocks.
Finally, there’s reporting and presentation. A table summary is not really affected by the unit (line vs statement vs blocks). The table is good for overview and to figure out where to focus, but the real value of coverage comes from understanding the interactions between code, tests, and data, which builds on relationships that are not always clear from the line-column constraints of the text file. The graph is a powerful aid for this.
On zcov
The preference for blocks over lines is not accidental - it is the fundamental idea in zcov, to abandon the traditional line coverage metrics in favour of block oriented ones, provide useful, intuitive, and powerful visualisations for them, and good querying support.
In fact, the zcov report summary does not even include line coverage at all, it has been replaced with block coverage. Here are some screenshots of the latest developments:
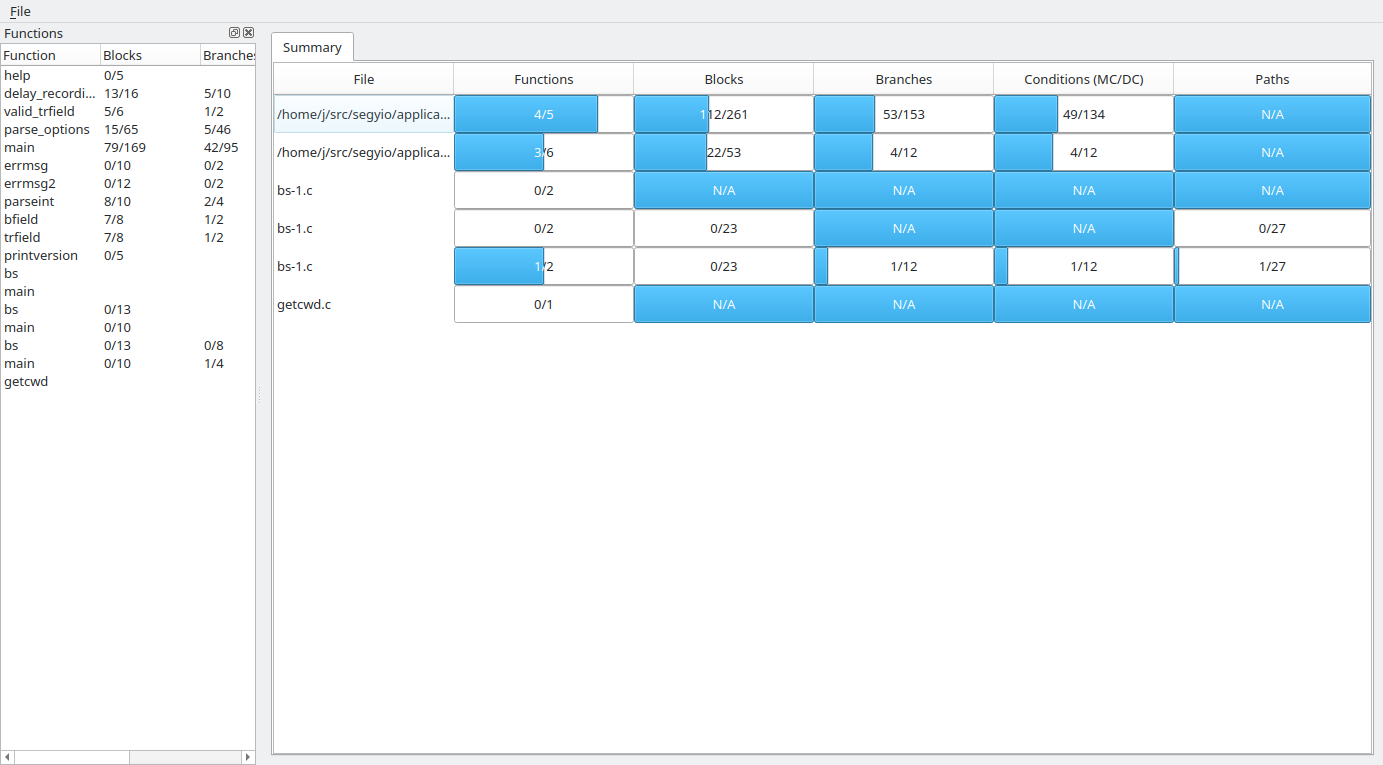
This is the summary of all the files in the loaded report. Relative progress is indicated with progress bars with the coverage count as labels. I plan to add colour support, sorting and filtering, and more, but already it is very useful for quickly interpreting the state of the coverage.
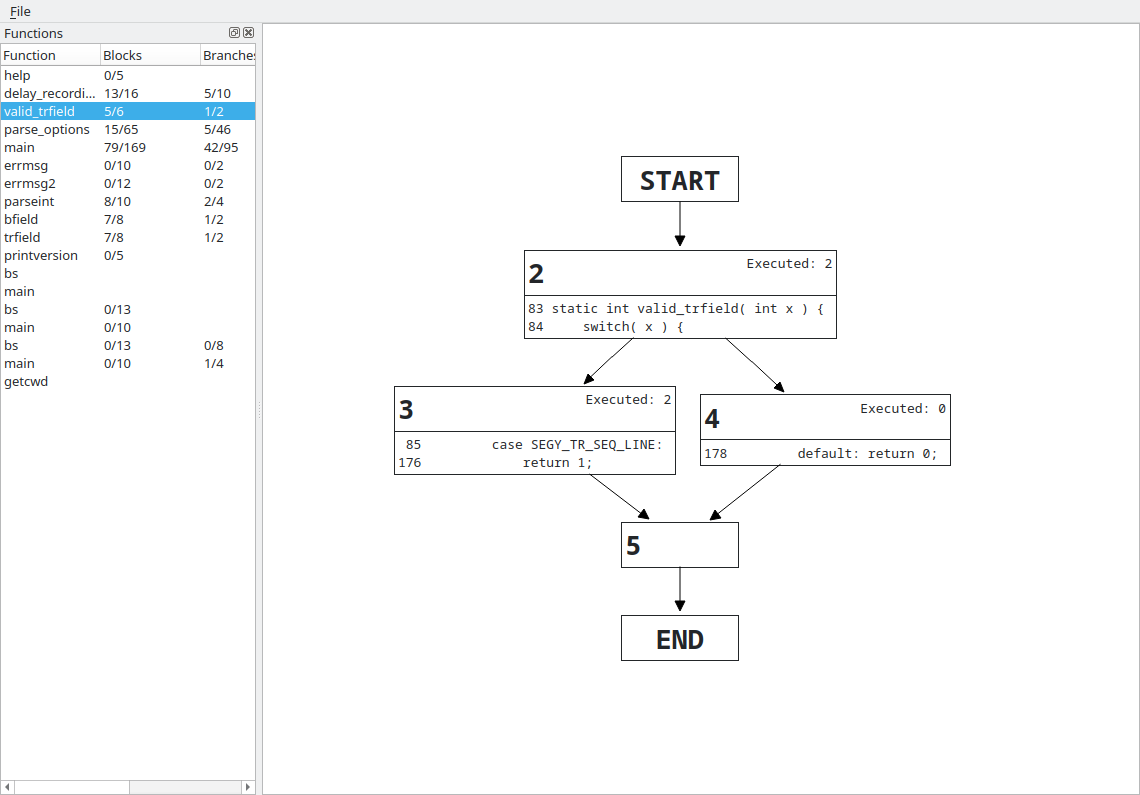
This is a simple graph. I have re-done most of the node rendering and extended the header to show the basic block ID, plus room for other interesting data such as the execution count. This view, too, will get querying and filtering support, plus highlighting of covered/uncovered nodes, paths, etc.
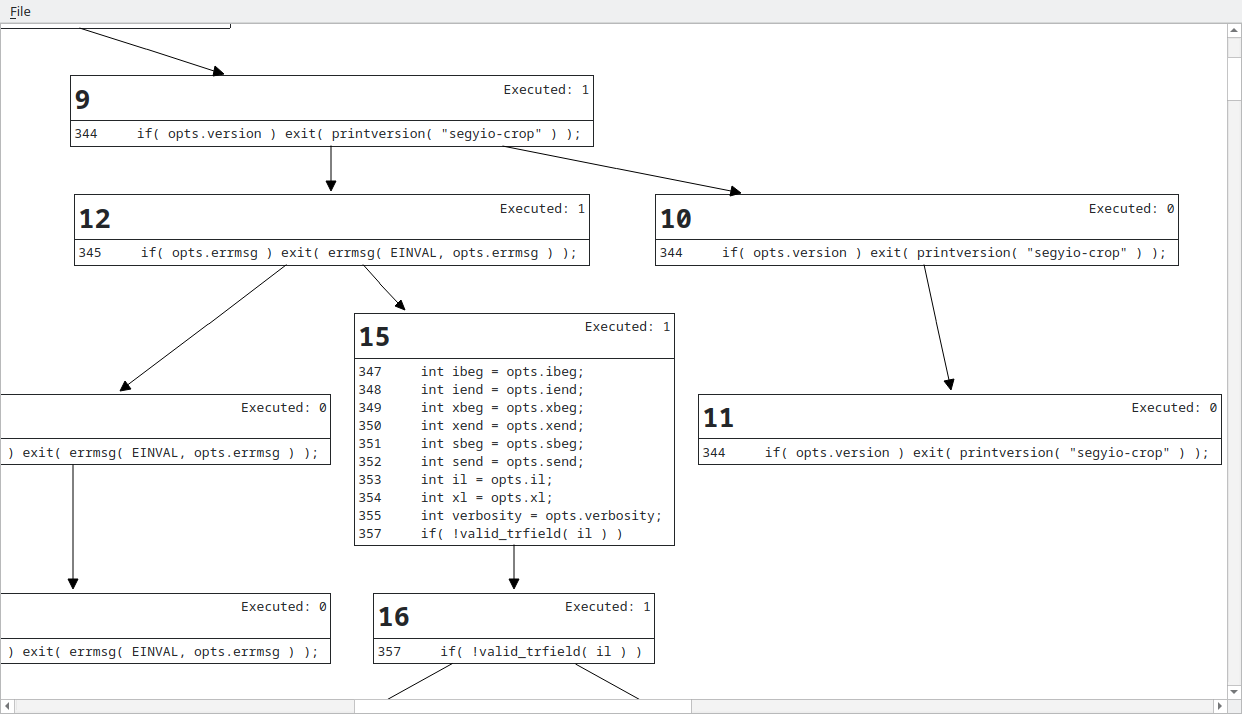
This is a neat demonstration of block-based coverage and divorcing
lines from coverage. Block 15 has many more statements than the
blocks around it, and you can clearly see the data flow and the effect
of taking branches. The exit() is even clearly captured as a leaf.
It still maps code to blocks at the line level, so the repeated ifs
look a bit odd, something I hope to improve in the future.
zcov is developing rapidly. For inquiries and purchases, reach out to j@patch.no, and see the software page for more details.